查询执行 在数据库查询执行中,查询管道(pipelining)和物化(materialization)是两种核心的执行模型。查询管道通过让元组在操作符之间持续流动,实现了流水线式的处理,从而减少了中间结果的写入和读取开销;而物化模型则在每个操作之后将中间结果保存为临时表,再由下一个操作读取,便于管理和重用,但会引入额外的 I/O 和存储成本。
在数据库查询执行中,要在既定的查询计划不变的前提下进一步提升性能,常见的三大技术杠杆正好对应经典的 CPU 性能方程 :
C P U T i m e = I n s t r u c t i o n C o u n t × C y c l e s P e r I n s t r u c t i o n × C l o c k C y c l e T i m e
\text{CPU Time} = \text{Instruction Count} \times \text{Cycles Per Instruction} \times \text{Clock Cycle Time}
C P U T i m e = I n s t r u c t i o n C o u n t × C y c l e s P e r I n s t r u c t i o n × C l o c k C y c l e T i m e 。
基于这一方程,我们可以通过以下三种途径分别作用于各项,从而整体降低查询的执行时间。
减少指令数 :通过让同样的计算工作消耗更少的指令,直接降低方程中的 Instruction Count 。
解决方案:
算法与逻辑优化 :在查询执行层面,合并相邻的过滤或算子,避免产生冗余的中间操作,如将多重过滤合并成单次扫描中的复合条件。编译器与JIT优化 :利用现代数据库的即时编译(JIT)技术,将高频 SQL 模板编译成高效机器码,去除不必要的抽象层次。简化控制流 :减少分支与函数调用,利用内联(inlining)与分支预测友好的代码组织,降低分支错判带来的指令重执行。
降低每条指令的平均周期数 :在保证指令数大致不变的情况下,通过加速每条指令的执行来降低平均周期数,使得每个周期内能执行更多的指令。
解决方案:
向量化执行 :一次处理多个数据元素(SIMD),使单条指令能够并行作用于多份数据,显著减少每元素的平均周期开销。缓存友好布局 :优化内存访问模式、减少缓存未命中、利用预取(prefetch)技术,降低内存访问延迟对 CPI 的影响。流水线与乱序执行 :让 CPU 同时处理多条指令的不同阶段,掩盖指令间的依赖与等待,提高指令吞吐能力。
并行化执行 :利用多线程/多进程将查询拆分为若干可并行处理的子任务,以共享整个系统的计算资源。
解决方案:
并行扫描 (Parallel Scan) :将表或分区划分为多个数据块,每个 worker 进程或线程独立扫描其负责的数据块。并行聚合 (Parallel Aggregation) :类似 MapReduce,在每个节点本地先做部分聚合,再在汇总阶段合并结果,降低网络与锁竞争开销。动态分区与调度 :根据实时负载与数据分布,自动调整任务划分与调度策略,避免因数据倾斜或节点瓶颈造成性能倒挂。
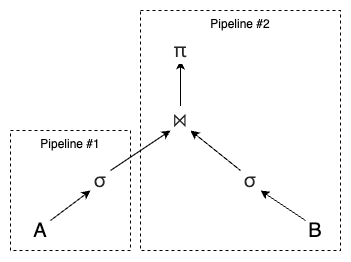
在现代关系型数据库中,**查询执行(Query Execution)**依赖于三个核心概念:查询计划、操作符实例和任务/流水线。查询计划被表示成一个操作符的有向无环图(DAG),它定义了不同运算节点及数据流依赖;操作符实例则是将某一操作符应用到数据的具体调用;任务(也称流水线)由一个或多个操作符实例顺序组成,在同一执行上下文中连续运行,从而实现元组的流式处理和高效并行执行。
假设我们要执行如下 SQL 命令:
1 2 3 4 SELECT A.id, B.valFROM A JOIN BON A.id = B.idWHERE A.val < 88 AND B.val > 214 ;
此时的查询执行的示意图如下:
但是在以上的查询执行中,会出现两种普遍发生的性能瓶颈:
指令依赖 :当一条指令的操作数依赖于前一条指令的输出时,就会出现数据依赖,导致后续指令必须等待前一指令完成写回,才能安全地执行。这会导致流水线停顿(Pipeline Stall),也就是依赖链未解除之前,流水线必须插入空周期,暂停取指与执行,直到数据可用。每出现一次停顿,均减少了可用的执行周期,尤其在长依赖链或深度流水线中,性能损失更为显著。
解决方案:
前递(Forwarding/Bypassing) :处理器在执行阶段即可将尚未写回的结果转发给下游指令,减少等待时间。指令重新排序(Out-of-Order Execution) :乱序发射允许非依赖指令先行执行,填补停顿周期,提高资源利用率。软件优化 :编译器或 JIT 在生成代码时,通过指令调度将依赖指令错开,或插入无关指令填充空档,降低数据冒险带来的停顿。
分支预测 :处理器在遇到分支指令时,会猜测分支是否成立,并预取/预执行分支路径上的指令,以保持流水线连续。这会导致流水线冲刷(Pipeline Flush) :若预测错误,必须将已加载但未提交的指令全部作废,并重新从正确目标地址逐级取指,造成数十至上百个周期的空闲;以及分支惩罚随流水线深度增加而增大 :深度更高的流水线需要冲刷更多级的指令,带来更高的性能损失。
缓解方案:
动态分支预测 :利用分支历史表(Branch History Table)等硬件结构根据过去执行情况进行预测,大幅提高准确率。无分支代码 :使用位运算和逻辑运算消除显式的 if 判断语句,从而让 CPU 不依赖分支预测。索引下推 :将分支条件判断尽量前移到索引扫描阶段,减少进入后续流水线的无效数据。向量化执行 :批量处理多条记录,将过滤逻辑应用于整个向量数组,在单条循环中执行多次条件判断并记录掩码,减少分支次数。
[!NOTE]
数据库中的分支失误:过滤操作
在顺序扫描过程中,每访问一行记录,都要执行对该行是否满足过滤条件的判断(if 语句),这构成了 DBMS 中最频繁 的分支指令序列。由于行数据的分布通常不可预测,过滤条件的真/假结果几乎是随机的,硬件分支预测器难以积累稳定的历史。
对于这种情况,我们可以采用无分支代码来解决。假设我们要执行如下命令:
1 SELECT * FROM user WHERE age > $(low) AND age < $(high);
那么这个 SQL 命令对应的有分支的代码如下:
1 2 3 4 5 6 7 8 i = 0 ; for (t in table) { key = t.key; if ((key > low) && (key < high)) { copy(t, output[i]); i = i + 1 ; } }
在以上代码中,每次 if 检查都生成一条或多条分支,过滤条件结果依赖于数据值分布,通常呈随机模式,硬件分支预测器难以积累有效历史,同时预测错误时需刷新流水线,放弃已取但未执行完的指令,造成 10–20 个周期的空洞。
因此我们可以将其改成无分支的代码:
1 2 3 4 5 6 7 i = 0 ; for (t in table) { copy(t, output[i]); key = t.key; delta = (key > low ? 1 : 0 ) & (key < high ? 1 : 0 ); i = i + delta; }
这段代码使用三目运算符和按位与(&)生成布尔掩码(0 或 1),避免 if 分支,消除了流水线刷新风险,可保持稳定的指令流,而且无分支的循环更符合 SIMD 自动向量化特性,编译器和 JIT 能将单条循环转换为批量处理指令,并利用 AVX/SSE 等向量指令集。
处理模型 在关系型数据库中,**处理模型(Processing Model)**决定了执行器如何遍历并执行优化器生成的查询计划树。不同处理模型在函数调用开销、中间结果管理、内存与 I/O 使用等方面各有取舍,因而对 OLTP(短事务、小结果集)与 OLAP(大批量分析查询)场景会产生截然不同的性能影响。
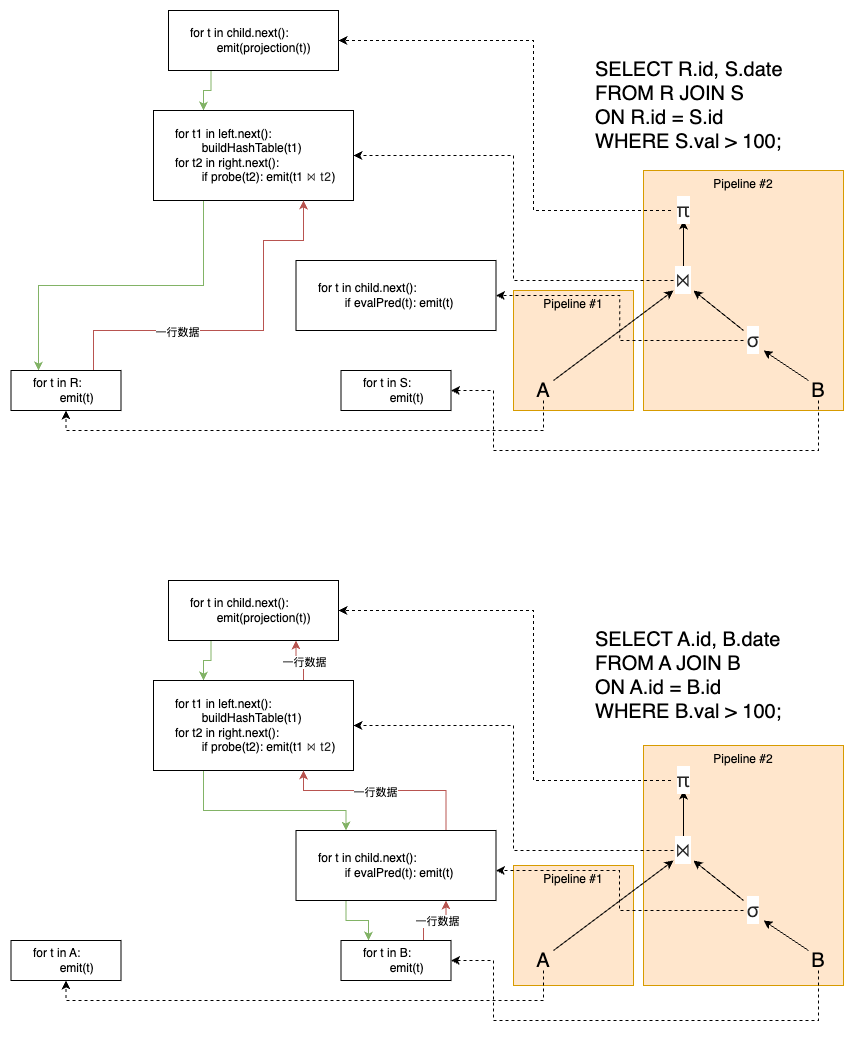
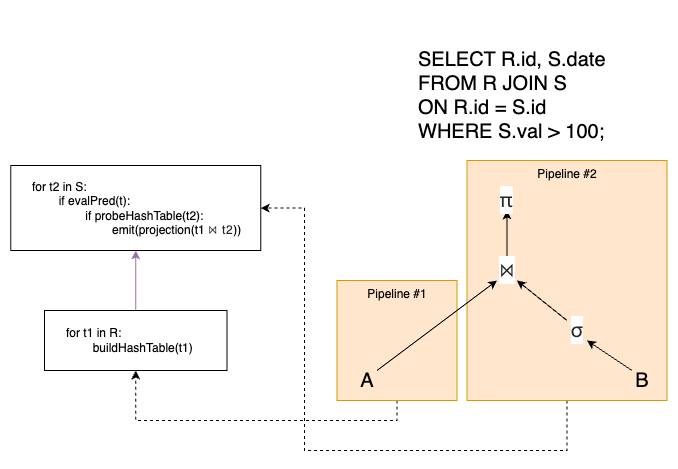
迭代器模型(Iterator / Volcano Model) 每个查询计划算子实现一个 next() 方法:调用时返回一个元组或标记结束(null),而且 next() 内部通常是一个循环:对子算子连续调用 next() 以获取下一个元组并进行处理,实现拉取式(pull-based)流水线 。
在该模型中,JOIN、ORDER BY 和子查询等算子却会一直被阻塞直到子算子发送完了所有的元祖。
下图展示了迭代器模型的执行流程,其中绿色箭头大小控制流,红色箭头代表数据流,之后的图都是如此:
上图中,在系统层面,这两个流水线各自由不同的执行线程或调度实体运行,可以在硬件资源(CPU 核、线程)许可下同时活跃。但哈希连接的建表阶段 是一个管道断裂点(pipeline breaker) :建表阶段只依赖 R 表,与 Pipeline #2 无关,因此当建表线程在后台扫描 R 时,Pipeline #2 可以同时并发进行 S 表的过滤。一旦建表完成,Pipeline #2 的探测阶段才会真正开始消费 Filter 的输出;如果 Filter 还没产出下一个符合条件的行,探测就会等待。反之,如果过滤很快,探测也会快速拉取并处理。
[!NOTE]
拉取式流水线中,调用者(上层算子或执行引擎)通过自顶向下的递归调用不断拉取数据,直到叶子算子从底层存储读取到元组并逐层返回。这种设计将控制流和数据流分离,上层算子负责驱动执行进程,下层算子被动提供数据,适合行级的管道处理。
优点:
内存占用小 :元组生成后可立即沿计划树上下游传递,无需完整物化中间结果。早期返回 :可以在部分数据处理完后就立即返回这部分的结果。
缺点:
函数调用开销 :深度计划树和高频 next() 调用在高并行度或大结果集场景下带来显著开销。难以并行化 :对多核或批处理的支持不够友好。
因此,该模型在 OLTP 场景中表现优异。
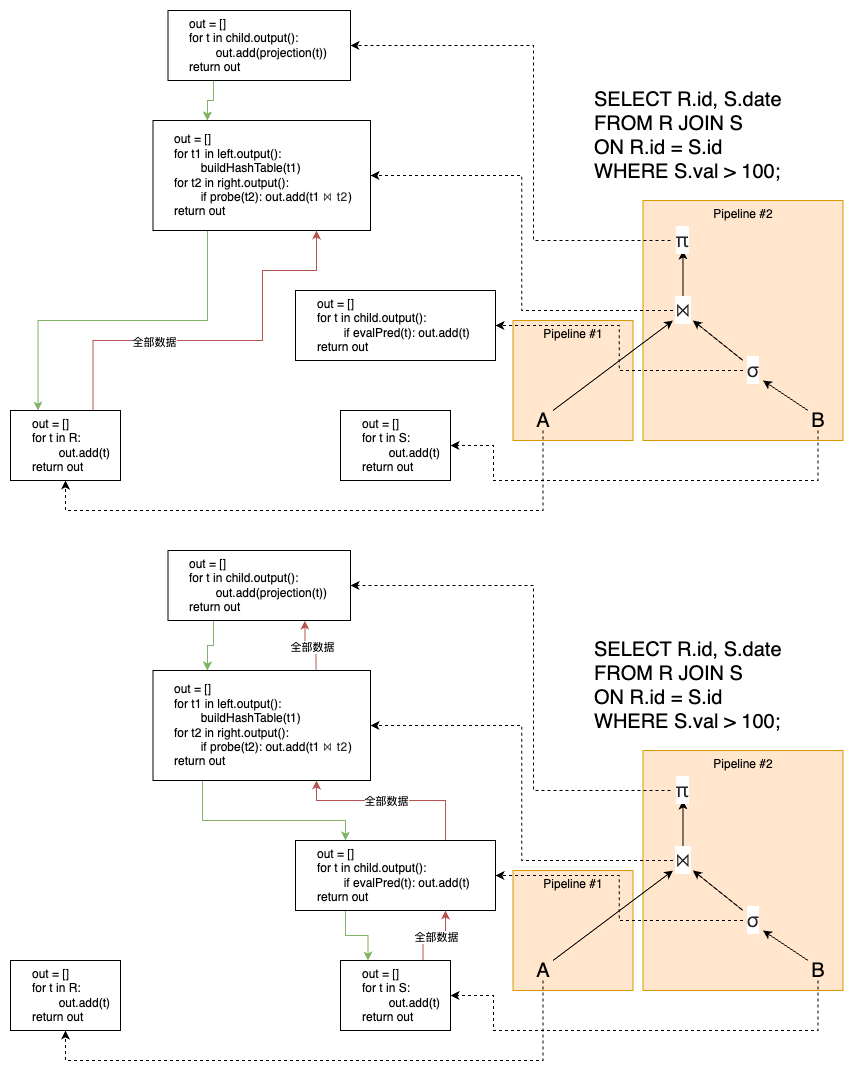
物化模型(Materialization Model) Materialization 模型是数据库管理系统中常见的查询执行模型之一,其中每个操作符一次性处理所有输入并一次性输出所有结果,称为物化操作 。该模型适用于 OLTP 场景,因其函数调用较少、协调开销低,能够快速返回少量元组;但对于中间结果集庞大的 OLAP 查询,则可能因临时结果需要写入磁盘而导致性能下降 。DBMS 可通过下推诸如 LIMIT 的执行提示(hints)来避免扫描过多元组,并支持行式存储或列式存储的物化输出方式。
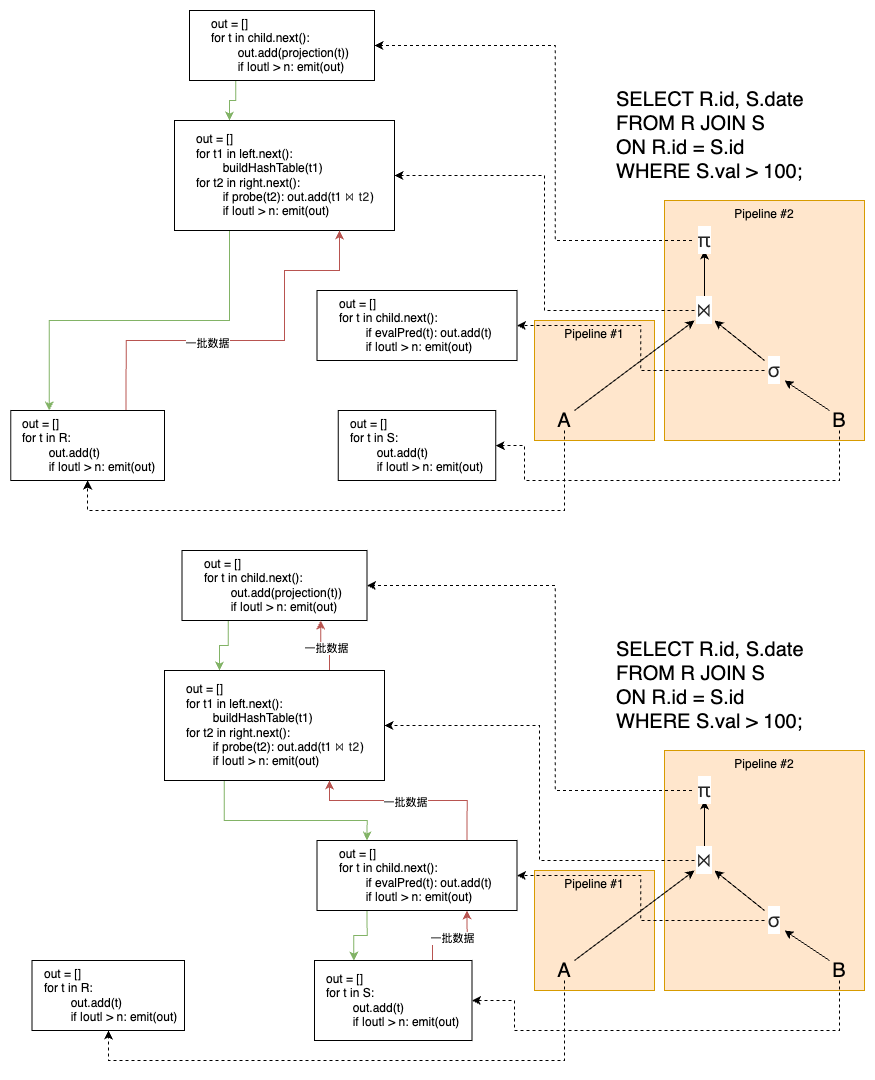
向量化模型(Vectorization Model)
Vectorization 模型是一种批量处理的查询执行策略,其中每个操作符在内部循环中一次性读取并处理一批(batch)的元组,然后一次性向外输出该批结果。这种方式通过利用现代 CPU 的 SIMD 指令加速批量数据处理,显著降低函数调用次数并提升缓存命中率,因而特别适合 OLAP 查询;但对于需要低延迟、逐一元组处理的 OLTP 工作负载,则并不理想。该模型的批大小可根据硬件能力(如 AVX 寄存器宽度)和查询属性动态调整,以实现最优性能。
每个查询操作符实现一个 next() 函数,但不是返回单个元组,而是返回一批元组。操作符的内部循环一次性在向量或批量数据上执行相同的操作,而非逐个元组调用。
需要强调的是,以上的三种处理模型都是属于 pull-based 的。
Pull 模型从根节点发起,通过连续调用 next() 向下拉取数据,适合传统行式、阻塞操作较多的场景;Push 模型则从叶子节点开始,将处理结果推送给父节点,并可在单一循环内融合多个算子,减少中间结果存储,更适合 OLAP 工作负载。
Push-based 模型的示意图如下:
Pull-based 和 Push-based 模型的对比 :
特性/模型 Pull(Top-to-Bottom) Push(Bottom-to-Top)
输出控制 易于对 LIMIT、TOP-N 等操作进行控制,父算子可随时停止拉取
不易实现 LIMIT,消费者难以及时通知生产者停止推送
管道阻塞支持 原生支持排序、聚合等阻塞算子
复杂算子需额外物化或流水线断点才能正确执行
函数调用开销 每条元组多次调用 next(),虚拟函数和分支跳转较多
同一循环内推送,函数和分支开销更低
缓存 & SIMD 利用 难以批量处理,SIMD 和缓存局部性利用有限
算子融合后易于批量处理,充分利用缓存和 SIMD
实现复杂度 基于 Volcano 模型,逻辑清晰、易于实现与维护
需算子融合、回调机制和调度框架,开发调试成本高
适用场景 OLTP、交互式小批量查询,带 LIMIT 的场景
OLAP、大规模扫描与聚合,列式存储与 MPP 系统