Intro
主要特点:
- 并行处理: Gamma 利用了分布式架构,通过将数据和计算任务分散到多个节点上并行处理,极大提高了查询性能和吞吐量。不同的节点可以同时处理不同的任务,从而加速整个系统的响应时间。
- 并行查询处理: Gamma 支持并行执行查询计划中的操作(如选择、投影、连接等)。系统采用流水线并行(pipelined parallelism)和分块并行(partitioned parallelism)技术来最大化资源利用率。
- 流式处理(Pipelining): Gamma 支持流式处理,即在一个操作产生部分结果时,直接将这些结果传递给下一个操作,而不是等待整个操作完成。这样可以减少内存占用,并加快查询处理速度。
- 数据分片(Declustering): Gamma 系统通过数据分片将数据表水平拆分成多个片段,并将这些片段分布到不同的处理节点上。这种方式不仅均衡了负载,还支持并行的查询处理,避免单点瓶颈。
- 动态负载均衡: Gamma 能够根据查询的工作负载,动态分配任务到不同的节点,确保整个系统的负载均衡,避免某些节点过载导致性能下降。通过监控每个节点的工作情况,Gamma 能够优化数据和任务分布。
- 故障容错(Fault Tolerance): Gamma 具有一定的故障容错能力,当某个节点出现故障时,系统可以通过冗余机制和数据复制,重新分配任务或从其他节点获取数据,避免系统中断。
- 扩展性(Scalability): Gamma 系统的设计能够随着节点的增加而线性扩展。通过增加处理节点,Gamma 可以处理更大规模的数据和更多的并发查询,保持高性能。
Gamma is based on the concept of a shared-nothing architecture in which processors do not share disk drives or random access memory and can only communicate with one another by sending messages through an interconnection network. Mass storage in such an architecture is generally distributed among the processors by connecting one or more disk drives to each processor.
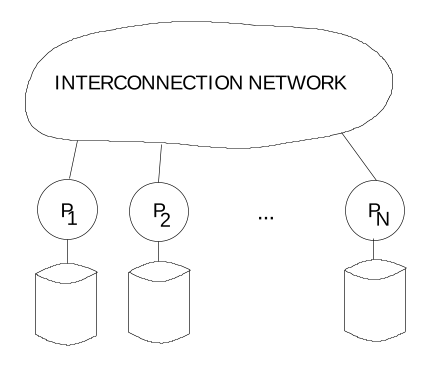
Reasons why the shared-nothing approach has become the architecture of choice.
- There is nothing to prevent the architecture from scaling to 1000s of processors unlike shared-memory machines for which scaling beyond 30-40 processors may be impossible.
- By associating a small number of disks with each processor and distributing the tuples of each relation across the disk drives, it is possible to achieve very high aggregate I/O bandwidths without using custom disk controllers
When Gamma’s system is figuring out the best way to run a query, it uses information about how the data is divided up (partitioned). This partitioning information helps the system decide how many processors (computers) need to be involved in running the query.
- For hash partitioning: If a table (say, “X”) is divided based on a hash function applied to a certain column (like “y”), and the query asks for records where “X.y = some value,” the system can directly go to the specific processor that holds the data matching that value.
- For range partitioning: If the table is divided based on ranges of values for a column, the system can limit the query to only the processors that have data within the relevant range. For example, if “X” is partitioned such that one processor handles values from 1 to 100, and another handles values from 101 to 200, then a query asking for “X.y between 50 and 150” will involve only the processors that have data in those ranges.
Different processes in the Gamma system work together. Here’s a simplified explanation of the main types of processes and their roles:
Catalog Manager: Acts like a “database encyclopedia,” storing all the information about data tables and structures. It ensures that data remains consistent when multiple users access the database.
Query Manager: Each user gets a query manager that handles query requests. It is responsible for parsing the query, optimizing it, and generating the execution plan.
Scheduler Processes: When a query is executed, the scheduler coordinates the execution steps. It activates the necessary operator processes (such as scan, selection, etc.) and ensures that all steps are performed in the correct order.
Operator Processes: These processes carry out specific database operations, like filtering data or joining tables. To reduce the startup delay during query execution, some operator processes are pre-initialized when the system starts.
Other Processes:
Deadlock Detection Process: Detects situations where two or more processes are stuck waiting for each other to release resources.
Recovery Process: Manages data recovery after a system failure.
How the Gamma system executes database queries?
- Query Parsing and Optimization: When a user submits a query, Gamma first parses it to understand what the query is asking for. Then, the system optimizes the query to find the most efficient way to execute it.
- Query Compilation: After optimization, the query is compiled into an “operator tree“ made up of different operations (such as scan, selection, join, etc.). This tree outlines the steps and the order in which the query will be executed.
- Single-Site vs. Multi-Site Queries: If the query only involves data on a single node (e.g., querying a small table), the system executes it directly on that node. However, if the query involves data distributed across multiple nodes (e.g., joining large tables), the system uses a “scheduler process” to coordinate the execution.
- Scheduler Coordination: The scheduler process is responsible for activating various operator processes across the nodes, such as instructing one node to scan data while another filters it. The scheduler also manages the flow of data between these operations, ensuring they happen in the correct order.
- Returning the Results: Once all operations are completed, the query results are collected and returned to the user. For queries embedded in a program, the results are passed back to the program that initiated the query.
Different operations (like scanning data, filtering, joining tables, etc.) are carried out in a parallel manner. Here’s a simplified explanation:
- Operator Processes: In Gamma, each operation in a query is handled by something called an “operator process.” For example, if the query needs to scan data from a table, filter some rows, and then join with another table, there would be separate operator processes for scanning, filtering, and joining.
- Data Flow: The data flows from one operator process to the next. For instance, the scan operator reads data from the disk and sends it to the filter operator, which then passes the filtered results to the join operator. This creates a kind of “data pipeline.”
- Split Table: Gamma uses a “split table” to decide where the data should go next. Think of it like a routing table that directs the flow of data. For example, if the data needs to be sent to multiple nodes for parallel processing, the split table helps determine which node each piece of data should go to.
- End of Processing: Once an operator finishes processing all its data, it closes its output streams and sends a signal to the scheduler process (which coordinates the whole query) to let it know that this part of the work is done.
In simple terms, the operator and process structure in Gamma is like an assembly line where data moves from one step (operator) to the next, with each operator performing a specific task, and the split table guiding the data flow. This setup allows the system to process data in parallel across multiple nodes, making it much faster.
Operators
Selection Operator
Data Spread Across Multiple Disks: In Gamma, data tables are split up and stored across multiple disks (this is called “declustering”). Because of this, when you want to search (select) for specific data, the system can perform the search in parallel across multiple disks.
Parallel Selection Process:
- If the search condition (predicate) matches the way the data is divided (partitioned), the system can narrow down the search to just the relevant nodes (computers with disks) that have the data. For example:
- If the data is divided using a hash or range partitioning method based on a certain attribute (like “employee ID”), and the search is also based on that attribute (e.g., “employee ID = 123”), then the search can be directed only to the node that holds data matching that condition.
- If the data is divided using a round-robin method (spreading data evenly across all disks) or if the search condition doesn’t match the partitioning attribute, then the system has to search on all nodes.
Performance Optimization:
- To make the search faster, Gamma uses a “read-ahead“ technique. This means that when it reads one page of data, it starts loading the next page at the same time, so that the processing of data can keep going without waiting for the next page to load.
Join Operator
Using Hash Partitioning: The join algorithms in Gamma are based on a concept called “buckets.” This means splitting the two tables to be joined into separate groups (buckets) that don’t overlap. The groups are created by applying a hash function to the join attribute (e.g., Employee ID), so that data with the same hash value ends up in the same bucket.
By partitioning the data into different buckets, each bucket contains unique data subsets, allowing parallel processing of these buckets, which speeds up the join operation. Additionally, all data with the same join attribute value is in the same bucket, making it easier to perform the join.
Gamma implements four different parallel join algorithms:
- Sort-Merge Join: Joins data by sorting and merging.
- Grace Join: A distributed hash-based join algorithm.
- Simple Hash Join: A straightforward hash-based partitioning join.
- Hybrid Hash Join: A combination of different join techniques.
Default to Hybrid Hash Join: Research showed that the Hybrid Hash Join almost always performs the best, so Gamma uses this algorithm by default.
Limitations: These hash-based join algorithms can only handle equi-joins (joins with equality conditions, like “Employee ID = Department ID”). They currently don’t support non-equi-joins (conditions like “Salary > Department Budget * 2”). To address this, Gamma is working on designing a new parallel non-equi-join algorithm.
Hybrid Hash-Join
- In the first phase, the algorithm uses a hash function to partition the inner (smaller) relation, R, into N buckets. The tuples of the first bucket are used to build an in-memory hash table while the remaining N-1 buckets are stored in temporary files. A good hash function produces just enough buckets to ensure that each bucket of tuples will be small enough to fit entirely in main memory.
- During the second phase, relation S is partitioned using the hash function from step 1. Again, the last N-1 buckets are stored in temporary files while the tuples in the first bucket are used to immediately probe the in-memory hash table built during the first phase.
- During the third phase, the algorithm joins the remaining N-1 buckets from relation R with their respective buckets from relation S.
The join is thus broken up into a series of smaller joins; each of which hopefully can be computed without experiencing join overflow. The size of the smaller relation determines the number of buckets; this calculation is independent of the size of the larger relation.
Parallel version of Hybrid Hash-Join
Partitioning into Buckets: The data from the two tables being joined is first divided into N buckets (small groups). The number of buckets is chosen so that each bucket can fit in the combined memory of the processors that are handling the join.
Storage of Buckets: Out of the N buckets, N-1 buckets are stored temporarily on disk across different disk sites, while one bucket is kept in memory for immediate processing.
Parallel Processing: A joining split table is used to decide which processor should handle each bucket, helping to divide the work across multiple processors. This means that different processors can work on different parts of the join at the same time, speeding up the process.
Overlapping Phases for Efficiency:
- When partitioning the first table (R) into buckets, Gamma simultaneously builds a hash table for the first bucket in memory at each processor.
- When partitioning the second table (S), Gamma simultaneously performs the join for the first bucket from S with the first bucket from R. This way, partitioning and joining overlap, making the process more efficient.
Adjusting the Split Table for Parallel Joining: The joining split table is updated to make sure that the data from the first bucket of both tables is sent to the right processors that will perform the join. When the remaining N-1 buckets are processed, only the routing for joining is needed.
Aggregate Operator
Parallel Calculation of Partial Results: Each processor in the Gamma system calculates the aggregate result for its own portion of the data simultaneously. For example, if the goal is to calculate a sum, each processor will first compute the sum for the data it is responsible for.
Combining Partial Results: After calculating their partial results, the processors send these results to a central process. This central process is responsible for combining all the partial results to produce the final answer.
Two-Step Computation:
- Step 1: Each processor calculates the aggregate value (e.g., sum, count) for its data partition, resulting in partial results.
- Step 2: The processors then redistribute these partial results based on the “group by” attribute. This means that the partial results for each group are collected at a single processor, where the final aggregation for that group is completed.
Update Operator
For the most part, the update operators (replace, delete, and append) are implemented using standard techniques. The only exception occurs when a replace operator modifies the partitioning attribute of a tuple. In this case, rather than writing the modified tuple back into the local fragment of the relation, the modified tuple is passed through a split table to determine which site should contain the tuple.
Concurrency Control
Gamma uses a two-phase locking strategy to manage concurrency. This means that before accessing data, a process must first acquire locks (first phase), and then release the locks after completing its operations (second phase). This ensures that multiple operations do not modify the same data at the same time, preventing conflicts.
Gamma supports two levels of lock granularity: file-level and page-level (smaller scope). There are also five lock modes:
- S (Shared) Lock: Allows multiple operations to read the data simultaneously.
- X (Exclusive) Lock: Only one operation can modify the data, while others must wait.
- IS, IX, and SIX Locks: Used to manage locking at larger scopes, such as entire files, allowing different combinations of read and write permissions.
Each node in Gamma has its own lock manager and deadlock detector to handle local data locking. The lock manager maintains a lock table and a transaction wait-for-graph, which tracks which operations are waiting for which locks.
The cost of setting a lock depends on whether there is a conflict:
- No Conflict: Takes about 100 instructions.
- With Conflict: Takes about 250 instructions because the system needs to check the wait-for-graph for deadlocks and suspend the requesting transaction using a semaphore mechanism.
Gamma uses a centralized deadlock detection algorithm to handle deadlocks across nodes:
- Periodically (initially every second), the centralized deadlock detector requests each node’s local wait-for-graph.
- If no deadlock is found, the detection interval is doubled (up to 60 seconds). If a deadlock is found, the interval is halved (down to 1 second).
- The collected graphs are combined into a global wait-for-graph. If a cycle is detected in this global graph, it indicates a deadlock.
When a deadlock is detected, the system will abort the transaction holding the fewest locks to free up resources quickly and allow other operations to proceed.
Recovery and Log
Logging Changes:
When a record in the database is updated, Gamma creates a log record that notes the change. Each log record has a unique identifier called a Log Sequence Number (LSN), which includes a node number (determined when the system is set up) and a local sequence number (which keeps increasing). These log records are used for recovery if something goes wrong.
Log Management:
- The system sends log records from query processors to Log Managers, which are separate processors that organize the logs into a single stream.
- If there are multiple Log Managers (M of them), a query processor sends its logs to one of them based on a simple formula: processor number mod M. This way, each query processor always sends its logs to the same Log Manager, making it easy to find logs later for recovery.
Writing Logs to Disk:
- Once a “page” of log records is filled, it is saved to disk.
- The Log Manager keeps a Flushed Log Table, which tracks the last log record written to disk for each node. This helps know which logs are safely stored.
Writing Data to Disk (WAL Protocol):
- Before writing any changed data (a dirty page) to disk, the system checks if the corresponding log records have already been saved.
- If the logs are saved, the data can be safely written to disk. If not, the system must first ensure the logs are written to disk before proceeding.
- To avoid waiting too long for log confirmations, the system always tries to keep a certain number of clean buffer pages (unused pages) available.
Commit and Abort Handling:
- Commit: If a transaction completes successfully, the system sends a commit message to all the relevant Log Managers.
- Abort: If a transaction fails, an abort message is sent to all processors involved, and each processor retrieves its log records to undo the changes using the ARIES algorithm, which rolls back changes in the reverse order they occurred.
Recovery Process:
- The system uses the ARIES algorithms for undoing changes, checkpointing, and restarting after a crash.
- Checkpointing helps the system know the most recent stable state, reducing the amount of work needed during recovery.
Dataflow scheduling technologies
- Data-Driven Execution Instead of Operator Control: Gamma’s dataflow scheduling lets data automatically move between operators, forming a pipeline. Each operator acts like a step on an assembly line: when data reaches the operator, it processes the data and then passes the processed results to the next operator.
- Reducing Coordination Overhead: Because of this dataflow design, the system does not need to frequently coordinate or synchronize the execution of each operator. This approach reduces the complexity and overhead of scheduling, especially when multiple operators are running in parallel, and avoids performance bottlenecks caused by waiting or synchronization.
- Inherent Support for Parallelism: Dataflow scheduling is well-suited for parallel processing because data can flow between multiple operators at the same time. For example, a query can simultaneously perform scanning, joining, and aggregation across different processors. Each operator can independently process the data it receives without waiting for other operators to finish, allowing the system to efficiently utilize the computational power of multiple processors.
- Adaptability to Dynamic Environments: During query execution, dataflow scheduling can be adjusted based on the actual system load and data characteristics. This flexibility allows the system to dynamically optimize the performance of query execution, especially for large and complex queries, by better adapting to changing query demands and system conditions.
Gamma’s unique dataflow scheduling techniques allow data to flow naturally between operators, reducing the need for direct control over operations. This significantly lowers coordination overhead in multi-processor environments, enhances the system’s parallel processing capabilities, and improves the efficiency of executing complex queries.
In Gamma’s dataflow scheduling techniques, parallelism is extensively used to improve query execution efficiency. Here’s where and how parallelism is applied:
Parallel Execution of Operators: Queries often involve multiple operators (e.g., scan, filter, join, aggregation). With dataflow scheduling, these operators can run in parallel:
Scan and Filter in Parallel: While one processor scans a data block, another processor can be filtering the data from previous blocks.
Parallel Joins: If a join operation involves large datasets distributed across different nodes, Gamma can perform the join operation on these different parts of the data simultaneously. The result of the join is computed in parallel across multiple processors.
Data Partitioning for Parallelism: The relations (data tables) are often partitioned across multiple processors in Gamma. This means that different processors can work on different partitions of the data at the same time. For example:
Partitioned Hash Joins: Data can be split into “buckets” based on a hash function, and different processors can handle the join for different buckets simultaneously.
Parallel Aggregation: When computing aggregate functions (e.g., sum or average), each processor calculates a partial result for its own partition of the data, and these partial results are later combined.
In summary, parallelism in Gamma is achieved through:
- Distributing query operators across multiple processors.
- Partitioning data so different processors work on different sections simultaneously.
- Enabling multiple stages of query execution (e.g., scanning, filtering, joining) to happen concurrently.
Questions
What is a fragment or a shard in Gamma?
A fragment or shard refers to a portion of a database relation that is horizontally partitioned across multiple disk drives.
How does a Gamma operator know where to send its stream of records?
There is a structure called split table to determine where each tuple should be sent, based on the values of tuples.
With interleaved declusttering, why not use a cluster size that includes all nodes in the system?
If an interleaved declustteing system includes all nodes, it will become more vulnerable to failures. The failure of any two nodes could make the data inaccessible. A smaller cluster will limits the risk of complete data unavailability and balance the load.
Hash-join is appropriate for processing equi-join predicates (Emp.dno = Dept.dno). How can Gamma process nonequi-join predicates (Emp.Sal > Dept.dno*1000) in a pipelined manner?
Range partitioning: Pre-partition the data based on ranges of values to reduce the search space.
Broadcast join: When the smaller relation is broadcasted to all nodes, and then each node evaluates the nonequi-join predicate in parallel.
Nested-loop join: Use a nested-loop join strategy where each tuple from one relation is compared against all tuples from the other relation.
What is the difference between Gamma, Google MapReduce, Microsoft Dryad and Apache Flink?
| Aspect | Gamma | MapReduce | Dryad | Flink |
|---|---|---|---|---|
| Primary Use | Parallel database queries | Batch processing | Graph-based parallel computation | Stream and batch processing |
| Architecture | Shared-nothing, partitioned data | Cluster-based, distributed | DAG of tasks | Distributed, supports DAG |
| Data Model | Relational operations (SQL-like) | Key-value pairs | Data flow in DAG | Stream processing with state |
| Partitioning | Horizontal partitioning | Data split into chunks | Data partitioned across graph | Data partitioned into streams |
| Fault Tolerance | Limited | Checkpointing | Task-level recovery | State snapshots, exactly-once |
| Programming | Relational (SQL-style) | Functional (Map/Reduce) | Sequential tasks in DAG | Functional, stream APIs |
| Scalability | Hundreds of processors | Horizontally across many nodes | Scales with more nodes | Highly scalable, stream and batch |
| Use Case | Database query processing | Log processing, data aggregation | Scientific computing | Real-time analytics, event processing |
Will a version of Gamma using FLOW be more modular than its current design?
Yes. FLOW enables more fine-grained control over the data flow and process interactions, which could simplify the addition of new operators and functionalities. It would also make the system easier to maintain and extend, as each component could be developed and optimized independently.
Reference: https://pages.cs.wisc.edu/~dewitt/includes/paralleldb/ieee90.pdf