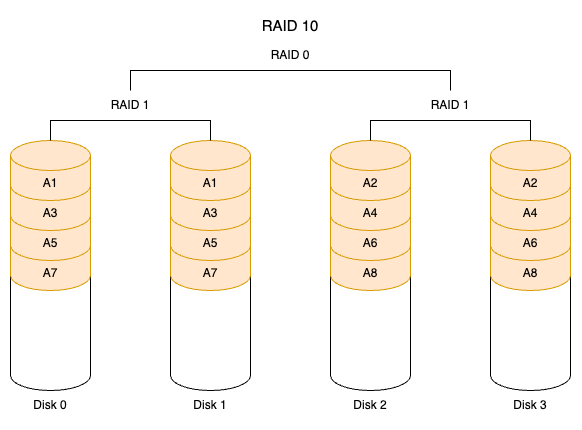
数据库的备份与恢复是一项最基本的操作与工作。在意外情况下(如服务器宕机、磁盘损坏、RAID 卡损坏等)要保证数据不丢失,或者是最小程度地丢失,每个开发者应该时刻关心所负责的数据库备份情况。
可以根据不同的类型来划分备份的方法。根据备份的方法不同可以将备份分为:
Hot Backup(热备)
Cold Backup(冷备)
Warm Backup(温备)
Hot Backup 是指数据库运行中直接备份,对正在运行的数据库操作没有任何的影响。这种方式在 MySQL 官方手册中称为 Online Backup(在线备份) 。Cold Backup 是指备份操作是在数据库停止的情况下,这种备份最为简单,一般只需要复制相关的数据库物理文件即可。这种方式在 MySQL 官方手册中称为 Offline Backup(离线备份) 。Warm Backup 备份同样是在数据库运行中进行的,但是会对当前数据库的操作有所影响,如加一个全局读锁以保证备份数据的一致性。
按照备份后文件的内容,备份又可以分为:
在 MySQL 数据库中,逻辑备份是指备份出的文件内容是可读的,一般是文本文件。内容一般是一条条 SQL 语句,或者是表内实际数据组成。如 mysqldump 和 SELECT * INTO OUTFILE 的方法。这类方法的好处是可以观察导出文件的内容,一般适用于数据库的升级、迁移等工作。但其缺点是恢复所需要的时间往往较长。
裸文件备份是指复制数据库的物理文件,既可以是在数据库运行中的复制(如 ibbackup, xtrabackup 这些工具),也可以是在数据库停止运行时直接的数据文件复制。这类备份的恢复时间往往较逻辑备份短很多。
若按照备份数据库的内容来分,备份又可以分为:
完全备份 是指对数据库进行一个完整的备份。增量备份 是指在上次完全备份的基础上,对下次更改的数据进行备份。日志备份 主要是指对 MySQL 数据库二进制日志的备份,通过对一个完全备份做完二进制日志的重做(replay)来完成数据库的 point-in-time 的恢复工作。MySQL 数据库复制(replication)的原理就是异步实时地将二进制日志重做传送并应用到从(slave/standby)数据库。
对于 MySQL 数据库来说,官方没有提供真正的增量备份的方法,大部分是通过二进制日志完成增量备份的工作。这种备份较之真正的增量备份来说,效率还是很低的。假设有一个 100GB 的数据库,要通过二进制日志完成备份,可能同一个页面要执行十多次的 SQL 语句完成真正做的工作。但是对于真正的增量备份来说,只需要记录当前页或最后的检查点的 LSN,如果大于之前全备时的 LSN,则备份该页,否则不用备份,这大大加快了备份的速度和恢复的时间,同时这也是 xtrabackup 工具增量备份的原理。
此外还需要理解数据库备份的一致性,这种备份要求在备份的时候数据在这一时间点上是一致的。举例来说,在一个网络游戏中有一个玩家购买了道具,这个事务的过程是:先扣除相应的金钱,然后向其装备表中插入道具,确保扣费和得到道具是互相一致的。否则,在恢复时,可能出现金钱被扣除了而道具丢失的问题。
对于 InnoDB 存储引擎来说,因为其支持 MVCC 功能,因此实现一致的备份比较简单。用户可以先开启一个事务,然后导出一组相关的表,最后提交。当然用户的事务隔离级别必须设置为 REPEATABLE READ ,这种做法就可以给出一个完美的一致性备份。然而这个方法的前提是需要用户事先设计应用程序。对于上述的购买道具的过程,不可以分为两个事务来完成,如一个完成扣费,一个完成道具的购买。若备份读操作发生在这两者之间,则由于逻辑设计的问题,导致备份出的数据依然不是一致的。
对于 mysqldump 备份工具来说,可以通过添加 --single-transaction 选项获得 InnoDB 存储引擎的一致性备份,原理和之前所说的相同,也就是,这时的备份是在一个执行时间很长的只读事务中完成的,来保证所有导出的表处于同一时间点的数据视图中。另外,对于 InnoDB 存储引擎的备份,务必加上 --single-transaction 的选项。如果不加这个选项,mysqldump 会对每个表分别 LOCK TABLES 并导出,会导致数据之间不一致(因为表导出存在先后顺序,前面表导出完了,后面表导出前可能已经被修改)。
最后,任何时候都需要做好远程异地备份,也就是容灾的防范。只是同一机房的两台服务器的备份是远远不够的。
冷备份 对于 InnoDB 存储引擎 的冷备非常简单,只需要备份 MySQL 数据库的 frm 文件、共享表空间文件、独立表空间文件(*.ibd)、重做日志文件。另外建议定期备份 MySQL 数据库的配置文件 my.cnf,这样有利于恢复的操作。
通常我们会写一个脚本来进行冷备的操作,可能还会对备份完成的数据库进行打包和压缩。关键在于不要遗漏原本需要备份的物理文件,如共享表空间和重做日志文件,少了这些文件可能数据库都无法启动。另一种经常发生的情况是由于磁盘空间已满而导致的备份失败,我们可能习惯性地认为运行脚本的备份是没有问题的,少了检验的机制。
正如前面所说的,在同一台机器上对数据库进行冷备是远远不够的,至少还需要将本地产生的备份存放到一台远程的服务器中,确保不会因为本地数据库的宕机而影响备份文件的使用。
冷备的优点是:
备份简单,只要复制相关文件即可。
备份文件易于在不同操作系统、不同 MySQL 版本上进行恢复。
恢复相当简单,只需要把文件恢复到指定位置即可。
恢复速度快,不需要执行任何 SQL 语句,也不需要重建索引。
冷备的缺点是:
InnoDB 存储引擎冷备的文件通常比逻辑文件大很多,因为表空间中存放着很多其他的数据,如 undo 区、插入缓冲等信息。
冷备也不总是可以轻易地跨平台。操作系统、MySQL 的版本、文件大小写敏感和浮点数格式都可能成为问题。
逻辑备份 mysqldump mysqldump 是 MySQL 官方提供的逻辑备份工具,用于将数据库中的结构和数据导出为 SQL 语句或其它文本格式,便于恢复、迁移或复制库。它支持单库、多库、单表或全库的备份,也能生成 CSV、XML 等格式文件。导出的文件可以在目标服务器上直接重执行,从而重建原始数据库对象和数据。
基本语法:mysqldump [连接选项] [备份选项] 库名 [表名...] > 备份文件.sql
如果要备份单库,可使用:mysqldump -u root -p --single-transaction mydb > mydb_backup.sql
如果要备份多库,可使用:mysqldump -u root -p --databases db1 db2 > multi_backup.sql
如果要备份全库,可使用:mysqldump -u root -p --all-databases > alldb.sql
如果是备份单表并按条件导出,可使用:mysqldump -u root -p mydb orders --where="order_date >= '2025-01-01'" > orders_jan.sql
如果是流式压缩备份,可使用:mysqldump -u root -p mydb | gzip > mydb.sql.gz
如果要恢复数据,可使用:mysql -u root -p mydb < mydb_backup.sql
mysqlpump mysqlpump 采用队列 + 线程模型,对象级并行:
队列 :可通过 --parallel-schemas 创建多个队列,每个队列可绑定一个或多个数据库。
线程 :在每个队列下可指定线程数(--default-parallelism),对同一队列内的对象(表、视图、存储过程等)并行导出。
导出对象为一系列可执行的 SQL 语句,包括 CREATE、INSERT、GRANT、CREATE TRIGGER/EVENT 等,可跨平台重现数据库结构与数据。
支持对象过滤:通过 --exclude-databases、--include-tables、--exclude-users 等选项灵活选择导出范围。
如果要全库并行备份,可使用:
1 2 3 4 5 6 7 8 9 mysqlpump \ --default-parallelism=4 \ --parallel-schemas=2 \ --add-drop-database \ --routines --triggers --events \ --users \ --compress \ --exclude-databases=information_schema,performance_schema \ > full_backup.sql.gz
恢复的操作和 mysqldump 的方法一致。
SELECT … INTO OUTFILE SELECT … INTO OUTFILE 用于将查询结果直接写入服务器主机上的文件,生成的文件可用于后续的批量导入或数据交换。该语句创建的文件必须在服务器文件系统中不存在,并且需要具备 FILE 权限才可执行。
如果要导出为 CSV 格式,可使用:
1 2 3 4 5 SELECT customer_id, firstname, surnameINTO OUTFILE '/var/lib/mysql-files/customers.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' ;
如果要恢复备份,可使用:
1 2 3 4 LOAD DATA INFILE '/var/lib/mysql-files/customers.csv' INTO TABLE mytableFIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' ;
或者
1 2 3 4 5 6 mysqlimport \ --local \ --fields-terminated-by=',' \ --fields-enclosed-by='"' \ --lines-terminated-by='\r\n' \ -u 用户 -p 数据库名 /var/lib/mysql-files/customers.csv
二进制日志的备份 二进制日志是 MySQL 实现 point-in-time 恢复和异步复制的关键:
point-in-time 恢复:在发生故障后,可以将完全备份与二进制日志配合,重放指定时间段或位置的变更,实现回滚到任意时间点。
默认情况下 MySQL 并不启用二进制日志,必须在 my.cnf 中添加:
1 2 [mysqld] log-bin = mysql-bin
仅启用 log-bin 不够保险,建议在 my.cnf 中也加上:
1 2 3 4 [mysqld] log- bin = mysql- bin sync_binlog = 1 innodb_support_xa = 1
sync_binlog=1:每次提交时强制将二进制日志刷盘,防止故障时丢失已提交的事务。
innodb_support_xa=1:开启 InnoDB 的 XA(分布式事务)支持,保证 binlog 与 InnoDB redo-log 在发生崩溃恢复时的一致性。
在备份二进制日志文件前,可通过 FLUSH LOGS 关闭当前日志文件并新建一个 binlog 文件,便于把之前那些日志一起备份。之后将 mysql-bin.00000* 等文件拷贝到安全位置,与完全备份一起存档。
恢复二进制日志
shell> mysqlbinlog [options] mysql-bin.000001 | mysql -u root -p test 可以将指定日志内容通过管道重放到目标库 test。shell> mysqlbinlog mysql-bin.00000[1-10] | mysql -u root -p test
先导出再 SOURCE 导入:
1 2 3 shell> mysqlbinlog mysql- bin.000001 > / tmp/ stmts.sql shell> mysqlbinlog mysql- bin.000002 >> / tmp/ stmts.sql shell> mysql - u root - p - e "SOURCE /tmp/stmts.sql"
我们也可以指定恢复的起始点:
按照偏移量:mysqlbinlog --start-position=107856 mysql-bin.000001 | mysql -u root -p test
按照时间:
1 2 3 mysqlbinlog mysql- bin.000001 | mysql - u root - p test
偏移量和时间选项的效果类似,都能实现仅重放二进制日志的部分内容。
热备份 ibbackup ibbackup 是 InnoDB 存储引擎官方提供的热备工具,可以同时备份 MyISAM 存储引擎和 InnoDB 存储引擎表。对于 InnoDB 存储引擎表,其备份工作原理如下:
记录备份开始时,InnoDB 存储引擎重做日志文件检查点的 LSN。
复制共享表空间文件以及独立表空间文件。
记录复制完表空间文件后,InnoDB 存储引擎重做日志文件检查点的 LSN。
复制在备份时产生的重做日志。
对于事务型数据库,如 Microsoft SQL Server 数据库和 Oracle 数据库,热备的原理大致相同。可以发现,在备份期间不会对数据库本身有任何影响,所做操作只是复制数据库文件,因此任何对数据库的正常操作都是允许的,不会被阻塞。
ibbackup 的优点有:
在线备份,不阻塞任何 SQL 语句。
备份性能好,实质上是复制数据库文件和重做日志文件。
支持压缩备份,通过选项可实现不同级别的压缩。
跨平台支持,可运行于 Linux、Windows 及主流 UNIX 平台。
ibbackup 对 InnoDB 存储引擎表的恢复步骤为:
恢复表空间文件。
应用重做日志文件。
ibbackup 提供了一种高性能的热备方式,是 InnoDB 存储引擎备份的首选方式。不过它是收费软件,并非免费。好在开源社区力量强大,Percona 公司推出了开源、免费的 XtraBackup 热备工具,它不仅实现了 ibbackup 的所有功能,还扩展了真正的增量备份能力。因此,更好的选择是使用 XtraBackup 来完成热备工作。
XtraBackup 文档请参考:https://docs.percona.com/percona-xtrabackup/8.4/
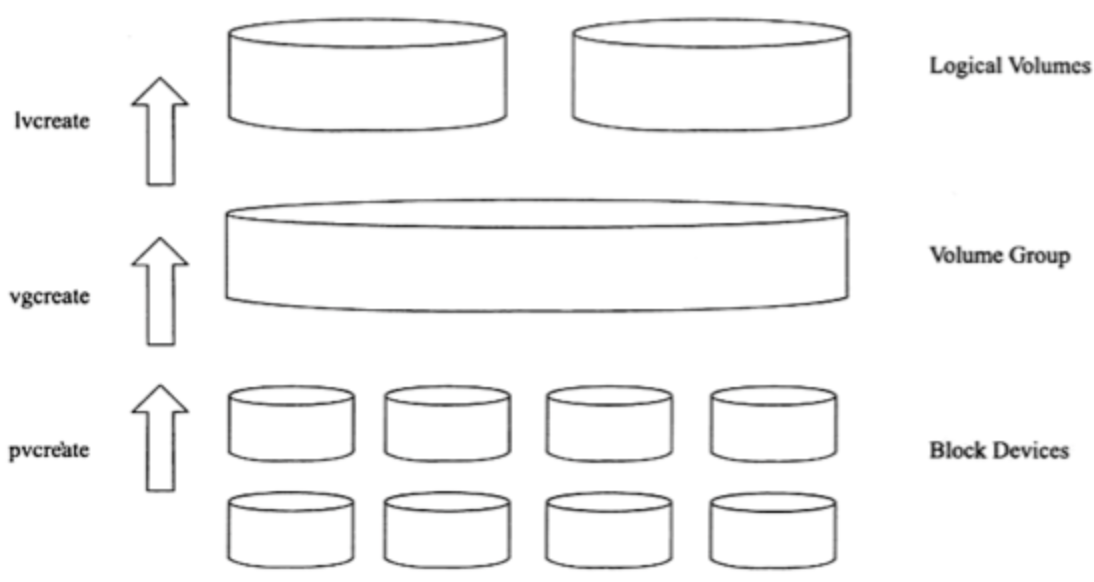
快照备份 MySQL 数据库本身不支持快照功能,因此快照备份是指通过文件系统支持的快照功能对数据库进行备份。备份的前提是将所有数据库文件放在同一个文件分区中,然后对该分区进行快照操作。支持快照功能的文件系统和设备包括 FreeBSD 的 UFS 文件系统、Solaris 的 ZFS 文件系统、GNU/Linux 的逻辑管理器(Logical Volume Manager,LVM)等。这里以 LVM 为例进行介绍。
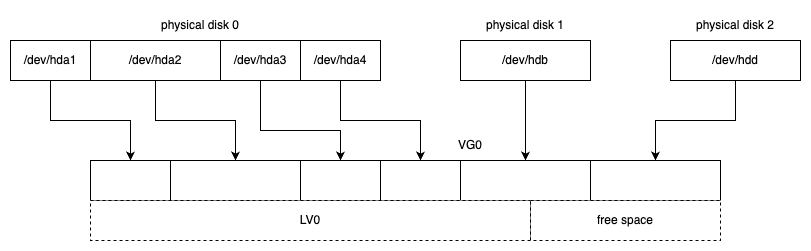
LVM 是 LINUX 系统下对磁盘分区进行管理的一种机制。LVM 在硬盘和分区之上建立一个逻辑层,来提高磁盘分区管理的灵活性。管理员可以通过 LVM 系统轻松管理磁盘分区,例如,将若干个磁盘分区连接为一个整体的卷组(Volume Group),形成一个存储池。管理员可以在卷组上随意创建逻辑卷(Logical Volumes),并进一步在逻辑卷上创建文件系统。管理人员通过 LVM 可以方便地调整卷组的大小,并且可以对磁盘存储按照组的方式进行命名、管理和分配。简单地说,用户可以通过 LVM 由物理块设备(如硬盘等)创建物理卷,由一个或多个物理卷创建卷组,最后从卷组中创建任意个逻辑卷(不超过卷组大小),如下图所示。
下图显示了由多块物理磁盘分区组成的逻辑卷 LV0。
Physical disk 0 拥有分区 /dev/hda1, /dev/hda2, /dev/hda3, /dev/hda4;Physical disk 1 拥有分区 /dev/hdb;Physical disk 2 拥有分区 /dev/hdd。
这些所有物理分区一起被加入到卷组 VG0 中,VG0 上划分出一个逻辑卷 LV0(图中左侧已分配区域),其余空间则作为 free space(图中右侧虚线区域)可供以后创建更多逻辑卷或扩展现有逻辑卷使用。
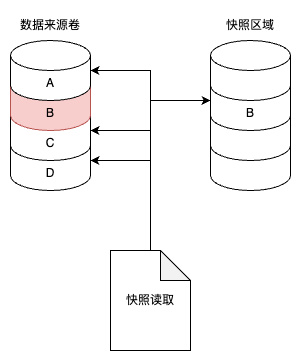
LVM 使用了写时复制(Copy-on-write)技术来创建快照。当创建一个快照时,仅复制原始卷中数据的元数据,并不会有数据的物理操作,因此快照的创建过程是非常快的。当快照创建完成,原始卷上有写操作时,快照会跟踪原始卷块的改变,将要改变的数据在改变之前复制到快照预留的空间里,因此这个原理的实现叫做写时复制。而对于快照的读取操作,如果读取的数据块是创建快照后没有修改过的,那么会将读取操作直接定向到原始卷上;如果读取的是已修改过的块,则将读取保存在快照中该块在原始卷上改变之前的数据。因此,采用写时复制机制保证了读取快照时得到的数据与快照创建时一致。
下图显示了 LVM 的快照读取,可见 B 区块被修改了,因此历史数据放入了快照区域。读取快照数据时,A、C、D 块还是从原有卷中读取,而 B 块就需要从快照读取了。
快照在最初创建时总是很小,当数据源卷的数据不断被修改时,这些数据才会放入快照空间,这时快照的大小才会慢慢增大。
为了让快照包含所有必要的数据,只要把 InnoDB 的所有相关文件(共享表空间文件、独立表空间文件、redo log 文件等)都放在同一个逻辑卷里。创建快照时,就会对整个逻辑卷进行一次时间点一致性的镜像。
在创建和使用 LVM 快照备份时,MySQL / InnoDB 不需要停机,应用仍可以继续正常读写。虽然备份过程中还有写操作在往磁盘上提交,但快照机制会保证备份那一刻的数据完整性,不会捕获到部分写入的脏状态。
当你用 LVM 快照恢复文件后,InnoDB 会像意外断电重启那样:自动扫描数据页和 redo log,决定哪些事务需要重做或回滚,最后恢复到一个一致的、可用的数据库状态。因此,用 LVM 快照做备份,恢复后就像给数据库做了一次意外重启,但数据完全一致且不会丢失已提交的事务。
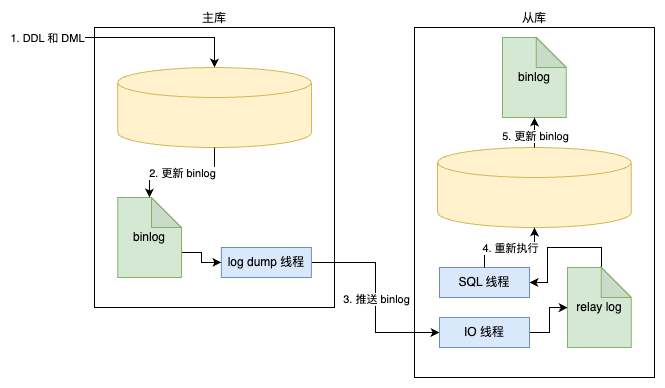
复制 复制(replication)是 MySQL 数据库提供的一种高可用高性能的解决方案,一般用来建立大型的应用。总体来说,replication 的工作原理分为以下 3 个步骤:
1)主服务器把数据更改记录到二进制日志中。
2)从服务器把主服务器的二进制日志复制到自己的中继日志(relay log)中。
3)从服务器重做中继日志中的日志项,把更改应用到自己的数据库上,以达到数据的最终一致性。
复制的工作原理并不复杂,其实就是一个完全备份加上二进制日志备份的还原。不同的是这个二进制日志的还原操作基本上实时在进行中。这里特别需要注意的是,复制不是完全实时地进行同步,而是异步实时。这中间存在主从服务器之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。复制的工作原理如下图所示。
从服务器有 2 个线程,一个是 I/O 线程,负责读取主服务器的二进制日志,并将其保存为中继日志;另一个是 SQL 线程,复制执行中继日志。因此如果查看一个从服务器的状态,应该可以看到类似如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 mysql> SHOW FULL PROCESSLIST\G * * * * * * * * * * * * * * * * * * * * * * * * * * * 1. row * * * * * * * * * * * * * * * * * * * * * * * * * * * Id: 1 User : system user Host: db: NULL Command: Connect Time : 6501 State: Waiting for master to send event Info: NULL * * * * * * * * * * * * * * * * * * * * * * * * * * * 2. row * * * * * * * * * * * * * * * * * * * * * * * * * * * Id: 2 User : system user Host: db: NULL Command: Connect Time : 0 State: Has read all relay log; waiting for the slave I/ O thread to update it Info: NULL * * * * * * * * * * * * * * * * * * * * * * * * * * * 3. row * * * * * * * * * * * * * * * * * * * * * * * * * * * Id: 206 User : root Host: localhost db: NULL Command: Query Time : 0 State: NULL Info: SHOW FULL PROCESSLIST 3 rows in set (0.00 sec)
可以看到 ID 为 1 的线程就是 I/O 线程,当前的状态是等待主服务器发送二进制日志。
ID 为 2 的线程是 SQL 线程,负责读取中继日志并执行。目前的状态是已读取所有的中继日志,等待中继日志被 I/O 线程更新。
在 replication 的主服务器上应该可以看到一个线程负责发送二进制日志,类似内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 mysql> SHOW FULL PROCESSLIST\G …… * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * 65. row * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * Id: 26541 User : rep Host: 192.168 .190 .98 :39549 db: NULL Command: Binlog Dump Time : 6857 State: Has sent all binlog to slave; waiting for binlog to be updated Info: NULL ……
之前提到 MySQL 的复制是异步实时的,并非完全的主从同步。若用户要想得知当前的延迟,可以通过命令 SHOW SLAVE STATUS 和 SHOW MASTER STATUS 得知。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 mysql> SHOW SLAVE STATUS\G * * * * * * * * * * * * * * * * * * * * * * * * * * * 1. row * * * * * * * * * * * * * * * * * * * * * * * * * * * Slave_IO_State: Waiting for master to send event Master_Host: 192.168 .190 .10 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql- bin.000007 Read_Master_Log_Pos: 555176471 Relay_Log_File: gamedb- relay- bin.000048 Relay_Log_Pos: 224355889 Relay_Master_Log_File: mysql- bin.000007 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: mysql.% ,DBA.% Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 555176471 Relay_Log_Space: 224356045 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: 1 row in set (0.00 sec)
以上结果中的各个字段的含义如下所示:
变量 说明
Slave_IO_State
当前 I/O 线程的状态,此例为 “Waiting for master to send event”(等待主库发送新的 binlog 事件)
Master_Log_File
当前从库正在读取的主库 binlog 文件名,本例为 mysql-bin.000007
Read_Master_Log_Pos
从库已读取到的主库 binlog 偏移位置(字节);本例 555176471 表示已读入约 529 MB(555176471/1024²)
Relay_Master_Log_File
从库中继日志对应的主库 binlog 文件名
Relay_Log_File
当前写入的中继日志文件名
Relay_Log_Pos
已执行到中继日志的偏移位置(字节)
Slave_IO_Running
从库 I/O 线程运行状态,YES 表示正常
Slave_SQL_Running
从库 SQL 线程运行状态,YES 表示正常
Exec_Master_Log_Pos
SQL 线程已执行到的主库 binlog 偏移位置;Read_Master_Log_Pos - Exec_Master_Log_Pos 即 I/O 与 SQL 线程之间的“字节延迟”
SHOW MASTER STATUS 可以用来查看主服务器中二进制日志的状态,如:
1 2 3 4 5 6 7 mysql> SHOW MASTER STATUS\G * * * * * * * * * * * * * * * * * * * * * * * * * * * 1. row * * * * * * * * * * * * * * * * * * * * * * * * * * * File: mysql- bin.000007 Position: 606181078 Binlog_Do_DB: Binlog_Ignore_DB: 1 row in set (0.01 sec)
可以看到,当前二进制日志记录了偏移量 606181078 的位置,该值减去这一时间点时从服务器上的 Read_Master_Log_Pos,就可以得知 I/O 线程的延时。
,用户不应仅监控从服务器上 I/O 线程和 SQL 线程是否运行正常,同时也应监控从服务器与主服务器之间的延迟,确保从服务器上的数据尽可能接近主服务器上的状态。
快照 + 复制的备份架构 复制可以用来作为备份,但功能不仅限于备份,其主要功能如下:
数据分布。由于 MySQL 数据库提供的复制并不需要很大的带宽要求,因此可以在不同的数据中心之间实现数据的复制。
读取的负载平衡。通过建立多个从服务器,可将读取平均地分布到这些从服务器中,并且减少了主服务器的压力。一般通过 DNS 的 Round-Robin 和 Linux 的 LVS 功能都可以实现负载平衡。
数据库备份。复制对备份很有帮助,但是从服务器不是备份,不能完全代替备份。
高可用性和故障转移。通过复制建立的从服务器有助于故障转移,减少故障的停机时间和恢复时间。
可见,只是用复制来进行备份是远远不够的。也就是说,仅靠主从复制无法完全防护数据丢失或误操作 ,需要结合从库的存储快照 和二进制日志重放 来实现对任意时间点的恢复与一致性保障。
假设当前应用采用了主从的复制架构,从服务器作为备份。此时,一个开发人员执行了误操作,如 DROP DATABASE 或 DROP TABLE,这时从服务器也跟着运行了。用户怎样从从服务器进行恢复呢?
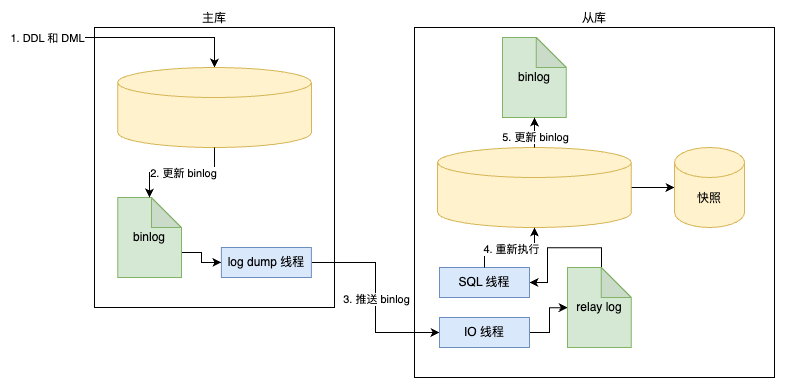
因此,一个比较好的方法是通过对从服务器上的数据库所在分区做快照,以此来避免误操作对复制造成影响。当发生主服务器上的误操作时,只需要将从服务器上的快照进行恢复,然后再根据二进制日志进行 point-in-time 的恢复即可。因此快照 + 复制的备份架构如下图所示。
还有一些其他的方法来调整复制,比如采用延时复制,即间歇性地开启从服务器上的同步,保证大约一小时的延时,可对抗误操作。这的确也是一个方法,只是数据库在高峰和非高峰期间每小时产生的二进制日志量是不同的,用户很难精确地控制。另外,这种方法也不能完全起到对误操作的防范作用。
此外,建议在从服务器上启用 read-only 选项,这样能保证从服务器上的数据仅与主服务器进行同步,避免其他线程修改数据。如:
在启用 read-only 选项后,如果操作从服务器的用户没有 SUPER 权限,则对从服务器进行任何的修改操作会抛出一个错误,如:
1 2 mysql> INSERT INTO z SELECT 2 ; ERROR 1290 (HY000): The MySQL server is running with the