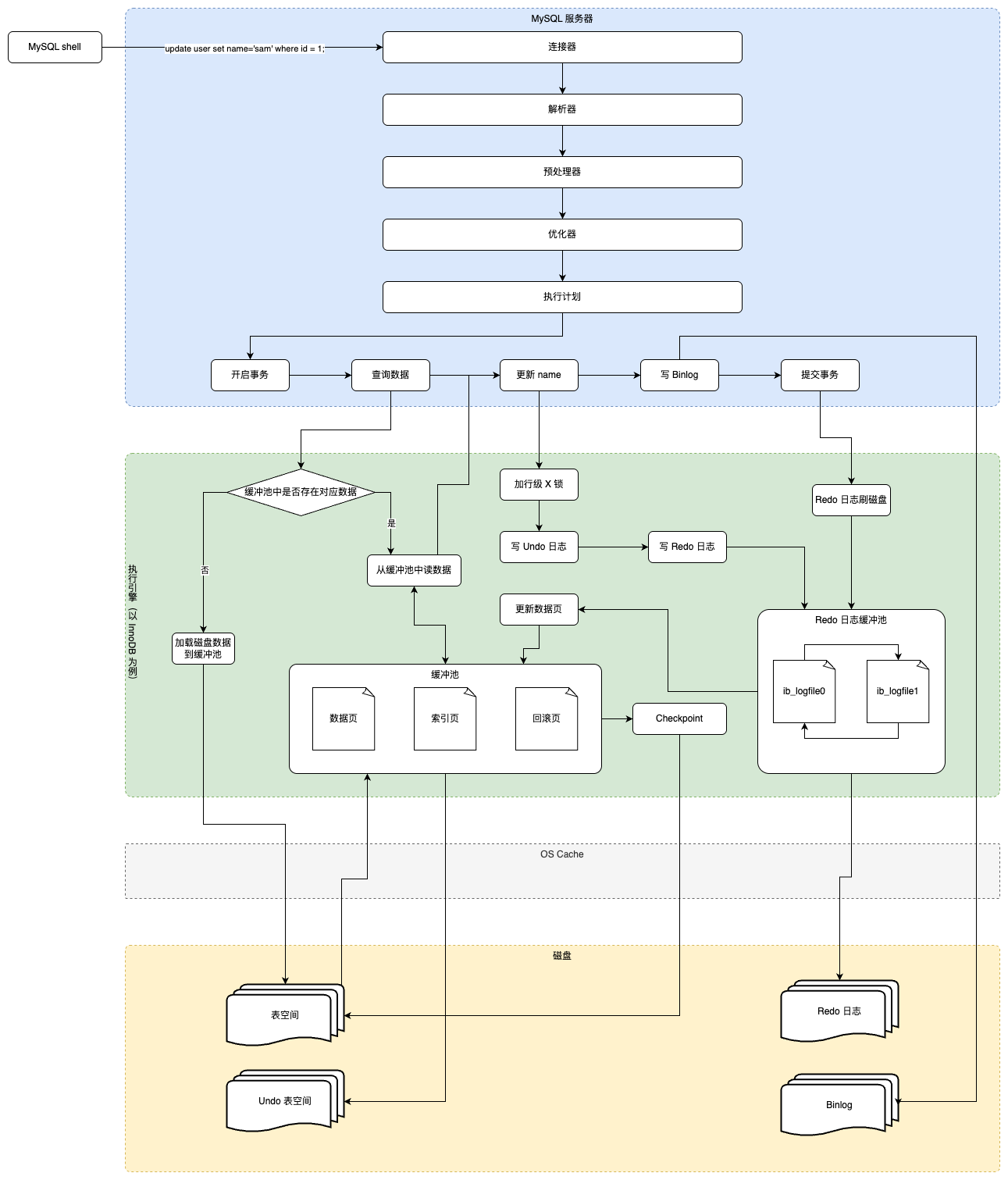
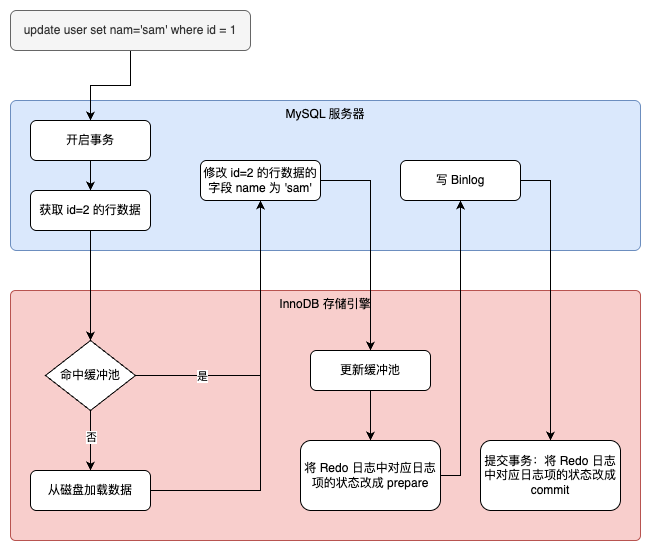
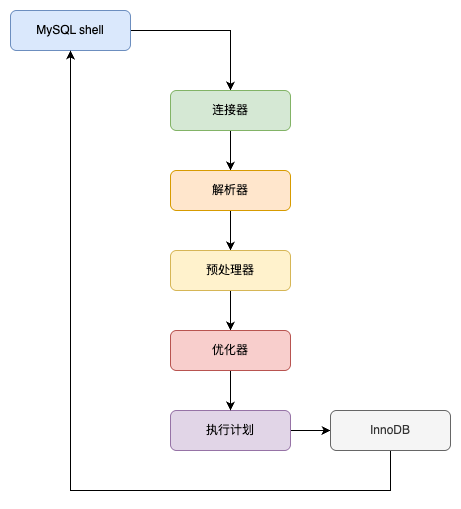
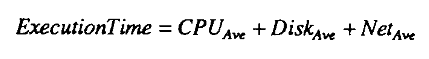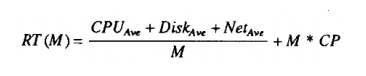ALTER TABLE user_info ADD school varchar(15) AFTER `level`; ALTER TABLE user_info CHANGE job profession varchar(10); ALTER TABLE user_info CHANGE COLUMN achievement achievement intDEFAULT0;
DML
给指定字段添加数据:INSERT INTO 表名 (字段1,字段2,...) VALUES (值1,值2);
给全部字段添加数据:INSERT INTO 表名 VALUES (值1,值2);
批量添加数据:
1 2
INSERT INTO 表名 (字段1,字段2,...) VALUES (值1,值2, ...), (值1,值2, ...), (值1,值2, ...); INSERT INTO 表名 VALUES (值1,值2,...), (值1,值2,...), (值1,值2,...);
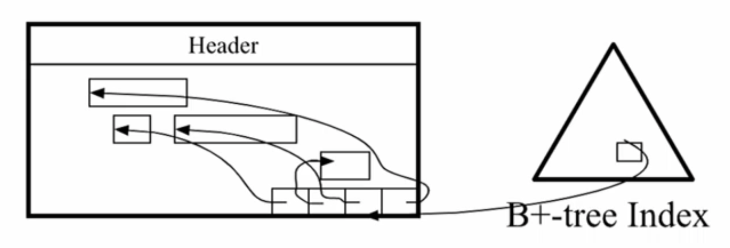
Each page consits of the header, the record space and a pointer array. Each slot in this array points to a record within the page.
A record is located by providing its page address and the slot number. The combination is called RID.
Life Cycle of a record:
Insert: Find an empty space to put it and set a slot at the very end of the page to point to it.
Delete: Remove the record and reclaim this space, set its slot number to null. When there are too many garbage slots, the system will drop the index structure, do reorganization on this disk page by removing all null slots, and reconstruct the index structure from scratch.
Non-clustered Index: the data of the disk page is independent of the bucket or leaf node of index.
Clustered Index: the data of the disk page resides within the bucket or leaf node of index.
Hash Index: the item in buckets is not ordered by the attribute value of index.
B+Tree Index: the item in leaf nodes is ordered by the attribute value of index.
Primary Index: the data in the disk page is ordered.
Secondary Index: the data in the disk page is not ordered.
The HRPS declusters a relation into fragment based on the following criteria:
Each fragment contains approximately FC tuples.
Each fragment contains a unique range of values of the partitioning attribute.
The variable FC is determined based on the processing capability of the system and the resource requirements of the queries that access the relation (rather than the number of processors in the configuration).
A major underlying assumption of this partitioning strategy is that the selection operators which access the database retrieve and process the selected tuples using either a range predicate or an equality predicate.
For each query Qi, the workload defines the CPU processing time (CPUi), the Disk Processing Time (Diski), and the Network Processing time (Neti) of that query. Observe that these times are determined based on the resource requirements of each individual query and the processing capability of the system. Each query retrieves and processes (TuplesPerQi) tuples from the database. Furthermore, we assume that the workload defines the frequency of occurrence of each query (FreqQi).
Rather than describing the HRPS with respect to each query in the workload, we deline an average query (Qavg) that is representative of all the queries in the workload. The CPU, disk and network processing quanta for this query are:
Assume that a single processor cannot overlap the use of two resources for an individual query. Thus, the execution time of Qavg on a single processor in a single user environment is:
As more processors are used for query execution, the response time decreases. However, this also incurs additional overhead, represented by the variable CP, which refers to the cost of coordinating the query execution across multiple processors (e.g., messaging overhead). The response time of the query on M processors can be described by the following formula:
In a single-user environment, both HRPS and range partitioning perform similarly because they both efficiently execute the query on the required processor. However, in a multi-user environment, the range partitioning strategy is likely to perform better because it can distribute the workload across multiple processors, improving system throughput. In contrast, HRPS might not utilize all available processors as effectively, potentially leading to lower throughput.
Instead of M representing the number of processors over which a relation should be declustered, M is used instead to represent the number of processors that should participate in the execution of Qavg. Since Qavg processes TuplesPerQavg tuples, each fragment of the relation should contain FC = TuplesPerQavg / M tuples.
The process of fragmenting and distributing data in HRPS:
Sorting the relation: The relation is first sorted based on the partitioning attribute to ensure each fragment contains a distinct range of values.
Fragmentation: The relation is then split into fragments, each containing approximately FC tuples.
Round-robin distribution: These fragments are distributed to processors in a round-robin fashion, ensuring that adjacent fragments are assigned to different processors (unless the number of processors N is less than the required processors M).
Storing fragments: All the fragments for a relation on a given processor are stored in the same physical file.
Range table: The mapping of fragments to processors is maintained in a one-dimensional directory called the range table.
This method ensures that at least M processors and at most M + 1 processors participate in the execution of a query.
M = N:系统和查询需求匹配,HRPS 调度所有处理器,达到最大并行度和最优性能。
M < N:HRPS 只调度一部分处理器执行查询,减少通信开销,但部分处理器资源可能闲置。
M > N:HRPS 将多个片段分配给处理器,尽量利用所有处理器,但每个处理器负担加重,查询执行速度可能受到影响。
HRPS in this paper supports only homogeneous nodes.
Questions
How does HRPS decide the ideal degree of parallelism for a query?
HRPS (Hybrid-Range Partitioning Strategy) decides the ideal degree of parallelism by analyzing the resource requirements of the query, such as CPU, disk I/O, and communication costs. It calculates the optimal number of processors (denoted as M) based on these factors. The strategy strikes a balance between minimizing query response time and avoiding excessive overhead from using too many processors.
Why is it not appropriate to direct a query that fetches one record using an index structure to all the nodes of a system based on the shared-nothing architecture?
Fetching one record should only involve the node that contains the relevant data, as querying all nodes wastes resources and increases response time.
How to extend HRPS to support heterogeneous nodes?
More powerful nodes would receive more fragments, while weaker nodes would handle fewer fragments.
The system could monitor node performance and dynamically adjust the degree of parallelism and fragment allocation based on current load and node availability.
Heavier tasks may be directed to more powerful nodes, while smaller or simpler queries could be executed on less powerful nodes.